Writing a compiler for Cool Programming Language
📅August 15, 2020 | ☕️20 minutes read
Recently, I have completed a Stanford Compilers MOOC. After almost two months of learning, I have managed to complete all coursework assignments which were implementing parts of a ‘real’ compiler. In the end, it was relatively easy to assemble them into a complete compiler which is a topic of this post. Overall, the course was a great experience, lectures were concise and reading list was awesome.
In this rather long post, I am going to describe the programming language for which compiler was written, as well as project structure and techniques used to implement it and test it. Here is a link to the project github repository.
Introduction
This project is a collection of four coursework assignments for the Stanford Compilers MOOC course. The result of completing all coursework assignments is a fully-working compiler for the COOL Programming Language. The compiler is written in C++ and depends on several assignment supplied libraries (like symbol table, identifiers table …). Flex and Bison are used to implement first compiler frontend phases and other compiler passes are hand coded in C++.
The compiler compiles COOL into MIPS Assembly. MIPS is a reduced instruction set architecture about which you can learn more here. Resulting programs are run using SPIM simulator.
COOL (Classroom Object Oriented Language) is a computer programming language designed by Alexander Aiken for use in a compiler course taught at Stanford. COOL resembles many modern programming languages including features such as objects, automatic memory management, strict static typing and simple reflection. COOL constructs take a few ideas taken from functional programming languages, so that every COOL statement is an expression which must return something. The fun fact is that there is a rumour there are more compilers for this language than programs.
COOL is precisely defined in specification documents, the most relevant ones are:
- describes lexical and syntactical structure of the language
- describes type system rules (equations) and language operational semantics
- describes the runtime system backing this programming language
- describes garbage collection algorithms used and the interface between those and a correct compiler
- describes the object layout recommended to implement this language and the interface to the garbage collection routines written in MIPS assembly language
Here are a few examples of simple COOL programs:
class Main inherits IO {
main(): SELF_TYPE {
out_string("Hello, World.\n")
};
};class Main inherits IO {
pal(s : String) : Bool {
if s.length() = 0
then true
else if s.length() = 1
then true
else if s.substr(0, 1) = s.substr(s.length() - 1, 1)
then pal(s.substr(1, s.length() -2))
else false
fi fi fi
};
i : Int;
main() : Object {
{
i <- ~1;
out_string("enter a string\n");
if pal(in_string())
then out_string("that was a palindrome\n")
else out_string("that was not a palindrome\n")
fi;
}
};
};Project Structure
The compiler project consists of four programming assignments:
Lexer - writing Flex specification which generates lexer
- The input to the lexer is a string and the output is a stream of tokens
- Here is the assignment specification
Parser - writing Bison specification which generates LALR(1) parser
- The input to the parser is a stream of tokens and the output is an abstract syntax tree
- The abstract syntax tree is constructed using a simple syntax-directed translation
- Here is the assignment specification
Semantic Analyser - writing a pass for semantical analysis, mainly type checking
- The input to the semantic analyser is a raw abstract syntax tree and the output is the attributed abstract syntax tree
- Here is the assignment specification
Tree walk Code Generator - writing a pass for code generation using a naive tree walk algorithm, generating code for the ‘stack machine’). The input to the code generator is the attributed abstract syntax tree and the output is a file consisting of MIPS instructions. Here is the assignment specification
Although this structure of the project was (pre)determined by the course skeleton code, even the production-ready compilers use more or less the same conceptual structure. Since the problem compilers solve is very hard and there are many edge cases, it is beneficial to divide the compilation process into several stages, colloquially known as ‘passes’. Compilers are usually divided into two major groups of passes:
- frontend consisting of lexical, syntactical and semantical analysis
- backend consisting of optimisation passes commonly involving various intermediate language representations and code generation
In this project, the frontend phase are programming assignments PA2, PA3, PA4, while the backend phase is only programming assignment PA5.
For the production compiler structure example see the Rust compiler.
Compilation stages
Lexical analysis - lexing
Lexical analyis was implemented using a famous flex tool. Lexical specification of Cool language is fully specified in the manual and the lexer implementation is a just a single lexical specification file. Basically, the idea is to describe each token of a programming language as a regular expression and use the flex tool to generate the minimal automaton to recognise tokens of a programming language (in this case Cool). In the following code snippet, you can see how type and objects are being recognised. In this case, it was useful to augment ‘on token recognised’ to insert the recognised identifier into identifiers table.
DIGIT [0-9]
LOWERCASE_LETTER [a-z]
UPPERCASE_LETTER [A-Z]
TYPEID ("SELF_TYPE"|{UPPERCASE_LETTER}({LETTER}|{DIGIT}|"_")*)
OBJECTID ("self"|{LETTER}({LETTER}|{DIGIT}|"_")*)
{TYPEID} {
cool_yylval.symbol = idtable.add_string(yytext);
return (TYPEID);
}
{OBJECTID} {
cool_yylval.symbol = idtable.add_string(yytext);
return (OBJECTID);
}Syntactical analysis - parsing
After the lexical analysis is done, we parse the generated stream of tokens. In this case, since the grammar rules of language are verbose, we use the parse tree as abstract syntax tree. Although it is generally not the best practice to use the parse tree as the abstract syntax tree because it contains a lot of unuseful information, here it was a reasonable choice since productions in grammar were not too complex.
Parser was implemented using a famous bison tool. Similar to the lexer case, bison generates the LALR(1) bottom-up parsing automaton from the specification file. Each production is represented as a rule followed by the ‘on action recognised’ callback. This implementation is a variant of an ad-hoc syntax directed translation where every production callback builds the parse tree for the current expression from the already parsed smaller trees of subexpressions.
In the following code snippet, you can see how we specify productions and rules for building the parse tree.
expression :
...
| expression '+' expression
{
@$ = @3;
$$ = plus($1, $3);
}
| expression '-' expression
{
@$ = @3;
$$ = sub($1, $3);
}
| expression '*' expression
{
@$ = @3;
$$ = mul($1, $3);
}
| expression '/' expression
{
@$ = @3;
$$ = divide($1, $3);
}
| INT_CONST
{
@$ = @1;
$$ = int_const($1);
}
...Semantic analysis - typechecking
The goal of semantic analysis is to perform context-sensitive checks on the abstract syntax tree generated in previous stage/s. In case of a statically typed language, the output of semantic analyser could be the attributed syntax tree or a stream of errors usually involving incorrect usage of types or identifiers.
As previously stated, all of typing rules are rigourously defined in the Cool Manual document and the goal of this stage was to implement them correctly. Broadly speaking, there are two main objectives in the case of Cool programming language:
- Class inheritance graph verification
- Expression types verification
Since Cool supports object inheritance, method overriding and class protected attributes, the first step is to build an inheritance graph and ensure it is acyclic. The property of the graph being acyclic implies the class inheritance is valid and that there are not cyclic dependencies. However, due to specific rules in the language, we also need to ensure that methods are being overriden with the same argument type sequence and that protected attributes are used in the correct context.
Here is an example of class graph property check:
...
bool ClassTable::is_class_table_valid() {
if (!this->is_inheritance_graph_acyclic())
return false;
if (!this->is_type_defined(Main)) {
semant_error() << "Class Main is not defined.\n";
return false;
}
return true;
}
...Expression types verification is implemented as an inorder tree-walk algorithm. More precisely, the idea is to take a node of an abstract syntax tree and perform the following:
- depending on the node type, type check subexpressions
- perform node level type checks or identifier access checks
- compute the current node type from the node-level type checks and the subexpression types
Here is an example of addition expression type checking:
...
Symbol plus_class::type_check() {
Symbol left_type = e1->type_check();
Symbol right_type = e2->type_check();
if (left_type == Int && right_type == Int)
this->set_type(Int);
else
{
class_table->semant_error(this)
<< "Expected both arguments of operator +to be of type Int"
<< " but got arguments of types "
<< left_type
<< " and "
<< right_type
<< ".\n";
this->set_type(Object);
}
return this->get_type();
}We first type check the left operand, then type check the right operand and ensure those are both integers. The resulting expression type is an integer.
Code generation
Code generation for Cool was possibly the most challenging part of the project. The reason for this is the fact Cool is an object-oriented language. That requires well-defined memory object layout and consistency across the whole code generation phase. It is worth noting that code generation phase assumes that all phases previously discussed work correctly and that the input to the phase is the attributed abstract syntax tree of a valid program.
Cool object layout is specified in the COOL Runtime System. The reason why I did not implement it on my own is the fact Cool has a supplied garbage collector and runtime system library. So in case of implementing custom object layout, there had to be a low-level assembly wrapper around the given runtime system and the actual object layout. I have decided to keep things simple and implement according to the assignment and default runtime system specification.
In this case, the code generation phase can be conceptually divided in the following parts:
- building a class dependency tree
- traversing a class dependency tree while populating the information transferred from inheritance relationship
- constructing a compilation context for each class - involves processing class methods and attributes, assigning memory offsets to each method and attribute
- generation of dispatch tables for each class compilation context - dispatch tables are used to invoke a method call on the arbitrary heap object according to the known method offset in the dispatch table
- emitting code for each class compilation context - emits class prototype tables, dispatch tables and tables for inheritance checking
- emitting code for each class method
To illustrate everything state above, consider the Article class.
Class Article inherits Book {
per_title : String;
initArticle(
title_p : String,
author_p : String,
per_title_p : String
) : Article {
{
initBook(title_p, author_p);
per_title <- per_title_p;
self;
}
};
print() : Book {
{
self@Book.print();
out_string("periodical: ")
.out_string(per_title)
.out_string("\n");
self;
}
};
};Observe that class Article has print and initArticle methods as well as various methods inherited from the Book class and higher level inheritance chain which needs to be captured.
The object layout of a class is a consecutive block of memory in form of:
- class unique tag
- class size in words
- class dispatch table pointer
- class attributes in defined order, where inherited attributes appear before class attributes
The result from compiling the Article compilation context is the following assembly prototype definition:
Article_protObj:
.word 8
.word 6
.word Article_dispTab
.word str_const27
.word str_const27
.word str_const27
Article_dispTab:
.word Object.abort
.word Object.type_name
.word Object.copy
.word IO.out_string
.word IO.out_int
.word IO.in_string
.word IO.in_int
.word Book.initBook
.word Article.print
.word Article.initArticleTo simplify emitting MIPS code for various programming language constructs, it was useful to define the ‘macro’ like functions in C++ which write the MIPS code to the output stream according to their name and arguments. Here is an example of a few such:
...
static void emit_label_def(int label_code, ostream &stream)
{
emit_label_ref(label_code,stream);
stream << ":" << endl;
}
static void emit_fetch_int(char *dest, char *source, ostream& strream)
{
emit_load(dest, DEFAULT_OBJFIELDS, source, stream);
}
static void emit_beq(char *src1, char *src2, int label, ostream &stream)
{
stream << BEQ << src1 << " " << src2 << " ";
emit_label_ref(label, stream);
stream << endl;
}
...Now we come to the interesting part of generating the code for programming language constructs. The core idea is to walk through the abstract syntax tree and generate code for each expression node in the tree. This compiler is not the optimising one, so we ignore the register allocation problem and instruction scheduling complexity and just generate code for the ‘stack’ machine. Through the whole compilation process, we maintain the simple invariant that expression result lies in $a0 register which acts as a logical ‘top’ of the stack and we preserve the stack pointer $sp across the function activations.
We define code method on every abstract syntax tree node which takes output stream and code generation context. Code generation context provides interface to the current class definition being compiled and objects currently on the method frame, since the code can lie only inside class methods.
To illustrate how it works, consider the loop construct. To compile loop construct, we first allocate two labels, one for the loop begin entry and one for the loop exit entry. Then we emit the loop begin label where we generate code for the predicate expression. After that we have a result in the $a0 register and then we check whether the loop predicate is satisfied using the simple branch instruction. We emit the code for the loop body in the case for which predicate holds and we emit loop exit label for the case when the predicate does not hold.
The implementation looks similar to this code:
...
void loop_class::code(ostream &s, cgen_context ctx) {
int loop_begin_label = next_label();
int loop_exit_label = next_label();
emit_label_def(loop_begin_label, s);
// loop begin
pred->code(s, ctx);
emit_fetch_int(T1, ACC, s);
emit_beq(T1, ZERO, loop_exit_label, s);
// predicate holds
body->code(s, ctx); // execute body and loop again
emit_jump_to_label(loop_begin_label, s);
// predicate fails
emit_label_def(loop_exit_label, s);
emit_move(ACC, ZERO, s);
}
...Here is the result of compiling the initArticle method from Article class mentioned in this section:
Article.initArticle:
addiu $sp $sp -12
sw $fp 12($sp)
sw $s0 8($sp)
sw $ra 4($sp)
addiu $fp $sp 4
move $s0 $a0
lw $a0 20($fp)
sw $a0 0($sp)
addiu $sp $sp -4
lw $a0 16($fp)
sw $a0 0($sp)
addiu $sp $sp -4
move $a0 $s0
bne $a0 $zero label20
la $a0 str_const0
li $t1 30
jal _dispatch_abort
label20:
lw $t1 8($a0)
lw $t1 28($t1)
jalr $t1
lw $a0 12($fp)
sw $a0 20($s0)
move $a0 $s0
lw $ra 4($sp)
lw $s0 8($sp)
lw $fp 12($sp)
addiu $sp $sp 12
addiu $sp $sp 4
addiu $sp $sp 4
addiu $sp $sp 4
jr $ra Testing and Grading
Most compiler phases are tested using the automated scripts which generate test cases and run each phase on the generated test cases. Almost all scripts were provided by the skeleton coursework project. All compiler phases are written and treated separately (ex: semantic analysis depends on the reference parser and lexer instead of ones written in this repository). This is to ensure that each phase generates only its own mistakes since the mistakes made in previous phases could easily propagate in some later phase.
In the last phase (code generator), reference lexer, parser and semantic analyser are replaced by the ones written in this repository since they have shown 100% accuracy, so it was reasonable to treat them as correct, although it may be wrong. There were precisely 270 test cases across all phases. Complete testing report is available here.
Sample COOL Programs
In the examples folder, there are various example COOL programs. All of them come in pairs ({name}.cl, {name}.s) where {name}.cl is a COOL program code, while {name}.s is the corresponding MIPS assembly program compiled using the written compiler (coolc in the root of the repository). Some of them are very simple and illustrate only key features of the COOL language, but there a few ones which are quite advanced (take a look at lam.cl which builds lambda calculus representation of a simple program and compiles it into Cool).
One of the ‘graphical’ ones is cells.cl which models one-dimensional cellular automaton.
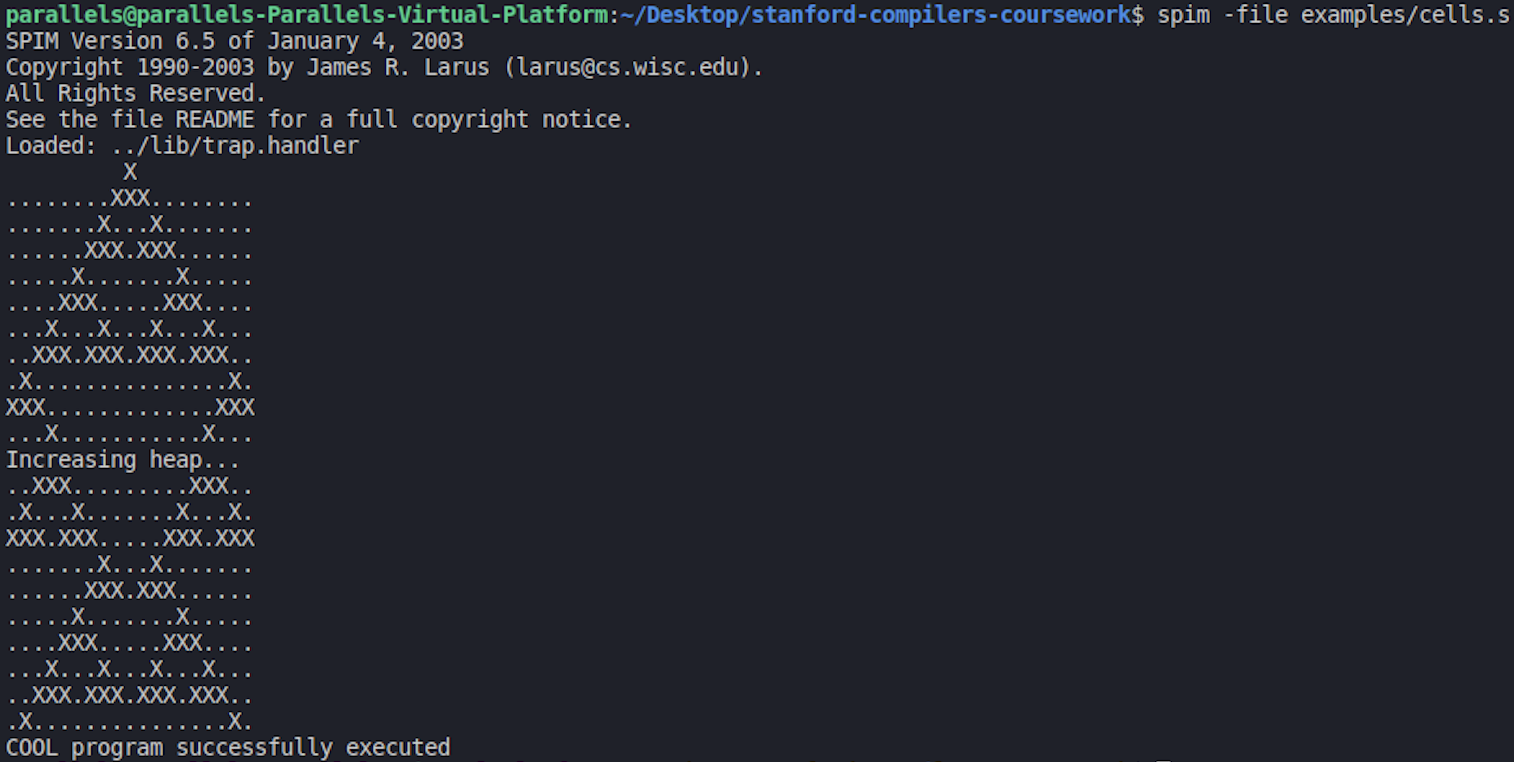
All of these programs were provided in the skeleton course project. You can find more about them here.
Potential improvements
Refactor complete project
Since this project was built in several assignments, due to the skeleton project build process it was hard to reuse some logic (like traversing the class inheritance graph) so the complete implementation of this compiler consists of only 5 files mentioned in project structure section which sometimes duplicate logic from previous steps.
After some analysis, I have realised it might be a better idea to rewrite the compiler from scratch using more clear build process in a separate repository
LLVM IR Implementation
Maybe compile to LLVM intermediate language to support more platforms out-of-the-box.
Conclusion
Overall, it was a great learning experience following the Stanford Compilers course and implementing a ‘real’ compiler along the way. Apart from the course materials provided, I have used Engineering a Compiler textbook to read more about theoretical aspects behind lexing, parsing and the best engineering practices in the world of ‘the’ real compilers. Book was well written, but some sections were a bit dry so it was very important to implement concepts presented.
This project made me appreciate the complexity of modern programming languages that we use on daily basis and take their capabilities for granted. Furthermore, it made aware about many engineering obstacles that production-ready compilers face, such as code optimisations using static single assignment forms, graph-coloring based register allocators and the complexity of testing the final implementations.
To sum up, I think compilers are real engineering masterpieces!